| Summary: | ASTERISK-27987: AGI() call causes RTP to briefly freeze under certain circumstances | ||
| Reporter: | xrobau (xrobau) | Labels: | patch pjsip |
| Date Opened: | 2018-07-25 20:10:32 | Date Closed: | 2018-08-14 10:07:45 |
| Priority: | Major | Regression? | No |
| Status: | Closed/Complete | Components: | Core/Bridging |
| Versions: | 15.5.0 | Frequency of Occurrence | Frequent |
| Related Issues: | |||
| Environment: | Attachments: | ( 0) agi-time.diff ( 1) broken.pcap ( 2) debug-server.txt ( 3) fdlist.txt ( 4) forktest.c ( 5) pcap1.png ( 6) pcap2.png ( 7) timer_list.txt | |
| Description: | "Something" causes Asterisk to get into a state where launching an AGI causes the entire process to freeze briefly.
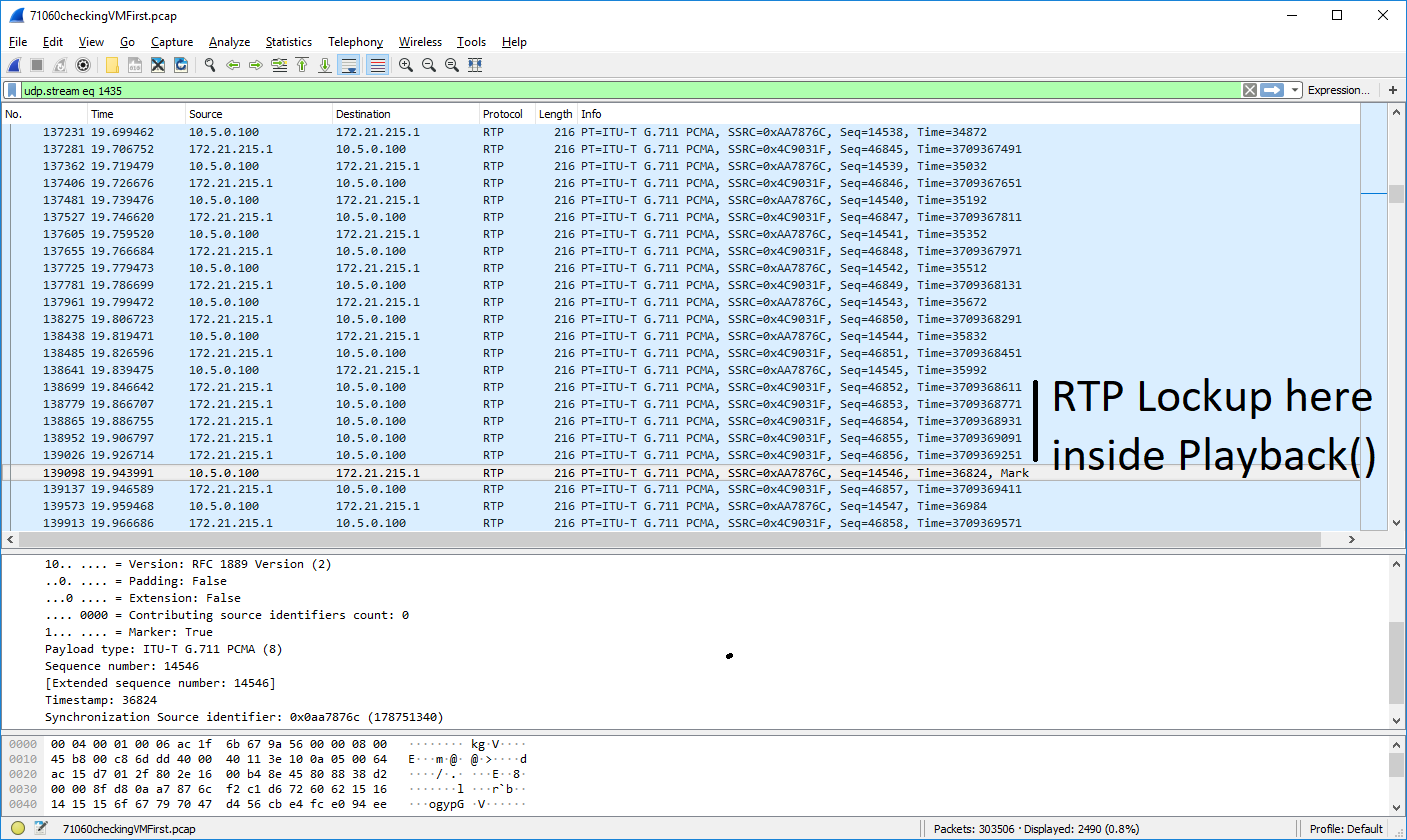
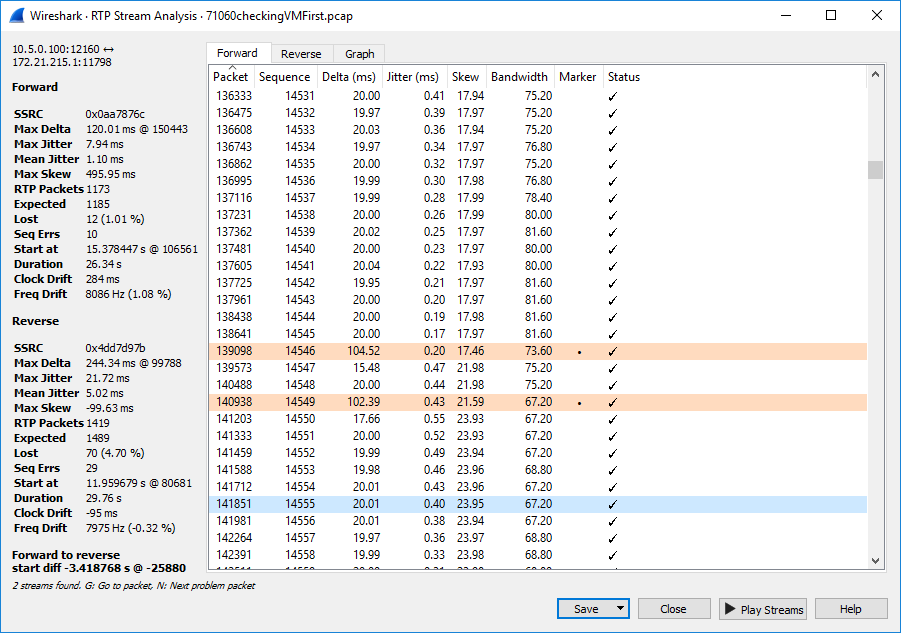
The symptoms are identical to ASTERISK-26257, but that is inaccurate as to the number of services that are impacted. Currently I am unable to create an artificial reproduction of the CAUSE, but the symptoms are extremely obvious. When Asterisk gets into this state (however it may occur) anything that is reading audio from the filesystem (MoH, Playback()/Background(), or Voicemail) OR confbridge conferences (not meetme) will briefly pause while an AGI is launched. We have numerous wireshark captures that show this happening (which we can attach if required), and the timestamps as generated by Asterisk are correct for when the packet WAS sent, not for when it SHOULD have been sent. This is triggered by AGI calls in dialplan. Our test dialplan to determine if Asterisk is in this state is as follows: {code} exten => 998,1,Answer same => n,Dial(Local/999@from-internal-custom/n,300,gm(default)) same => n,Playback(beep) same => n,Goto(1) exten => 999,1,Set(COUNT=0) same => n(loop),GotoIf($[ ${COUNT} > 1000 ]?toomany) same => n,Gosub(testtrigger) same => n,Set(COUNT=$[ ${COUNT} + 1 ]) same => n,Goto(loop) same => n(toomany),Hangup same => n(testtrigger),AGI(/bin/true) same => n,Return {code} If Asterisk is in this broken state, the MoH will be extremely choppy. After a restart of Asterisk, the MoH is not interrupted. We've also noticed that the loop runs MUCH slower when Asterisk is in this state. My random, and probably incorrect, hypothesis is that there's a core lock somewhere that is being grabbed by res_agi which is appending to a gradually growing list, or SOMETHING, that takes a longer and longer time, until it's locking up for longer than 20msec and blocking things that are reading from files (and whatever confbridge is doing) I ran that dialplan on a test machine, and was unable to get Asterisk into that state after 250,000 AGI calls. However, our (Sangoma)'s main PBX does randomly and sporadically experience this problem, and we've just got into the habit of restarting asterisk whenever we notice it, which has never been below 30,000 calls (calls as reported by 'core show calls'), and is almost certain to be in that state over 50,000 calls. The only common factor that is visible, so far, is that this only happens on Hardware, not in VMs (which may be a red herring), and that all the machines have a lot of listeners to AMI Events. Unfortunately, without any way to reproduce this, I'm aware that it's hard to proceed further. However, if there's any more information I can provide when a machine IS in this state, as to what may be causing it, please feel free to ask. Fixing it, as above, is as simple as 'core restart now'. The AGI loops runs fast, and the audio glitch vanishes. | ||
| Comments: | By: Asterisk Team (asteriskteam) 2018-07-25 20:10:33.767-0500 Thanks for creating a report! The issue has entered the triage process. That means the issue will wait in this status until a Bug Marshal has an opportunity to review the issue. Once the issue has been reviewed you will receive comments regarding the next steps towards resolution. A good first step is for you to review the [Asterisk Issue Guidelines|https://wiki.asterisk.org/wiki/display/AST/Asterisk+Issue+Guidelines] if you haven't already. The guidelines detail what is expected from an Asterisk issue report. Then, if you are submitting a patch, please review the [Patch Contribution Process|https://wiki.asterisk.org/wiki/display/AST/Patch+Contribution+Process]. By: xrobau (xrobau) 2018-07-25 20:56:19.474-0500 The timestamps Asterisk generate ARE correct, so the lockup is happening before there, internally. Attached are some screenshots of pcaps demonstrating the issue. The lockup is 100msec every time, in this pcap, but I hesitate to say that the lockups are ALWAYS at 100msec. I have, historically, felt that the lockup varied, but I have no actual data to back that statement up. By: Joshua C. Colp (jcolp) 2018-07-26 04:05:03.318-0500 There is no core lock or list that is shared for such a thing, the only thing that would be overlap in the process would be any filesystem access and the container for channels. AMI could have some stuff, but even if it were that wouldn't bubble up because it just consumes events as they come in and the sender isn't interrupted. Have you done any analysis of the underlying system to confirm things before jumping to Asterisk? I/O wait times? ioping? iotop? Checked process CPU usages? Anytime I've heard of this it's been hardware related in some way. By: xrobau (xrobau) 2018-07-26 04:16:07.041-0500 This is a problem in Asterisk. The system can be idle, and the AGI is /bin/true. Restarting Asterisk fixes the problem. I'm hoping that you can tell me where to look when it happens next time, so I can get some better debugging information. "Next time" will be on Monday or Tuesday. By: Joshua C. Colp (jcolp) 2018-07-26 05:18:26.859-0500 Nothing comes to mind, someone has to dig in deeply. It's not something I've ever heard of something experiencing and not something reported by anyone I've seen. You could try to grab a backtrace and see if anything looks out of the ordinary... From an Asterisk perspective there's nothing that comes to mind that can be done from a code perspective to deprive everything else such that everything suffers, except for consuming CPU to deprive other threads which would mean the system isn't idle. By: xrobau (xrobau) 2018-07-26 06:18:50.385-0500 This was reported in ASTERISK-26257, in 2016, but with the same inability-to-replicate, it was closed. Note: The state of the system is not relevant to the glitch. An idle or busy machine will do it. I mean, I can probably get you access to our pbx when it's doing it, but without knowing where to even START to look, I feel like I'm floundering around. The only clue that popped up is that it's freezing for almost exactly 100msec, which seems a suspiciously round number. Can you think of anything that could possibly BLOCK for 100msec before failing? What about if something was blocking AMI writes? As I mentioned above, the common factor in the two machines that are repeatedly doing this is that they have a lot of AMI Event Listeners. By: Joshua C. Colp (jcolp) 2018-07-26 06:27:49.269-0500 The publishing of an event doesn't block while writing out to AMI listeners. There's at least two queues in between, the stasis one and then one built into AMI itself. It's possible but unlikely. I don't know of anything off the top of my head for 100 milliseconds. By: xrobau (xrobau) 2018-07-26 06:43:44.877-0500 I think I may not have explained myself well, reading your comment. The only time that the audio glitches is when Asterisk is playing back audio from the filesystem (or, using confbridge, which does filehandle-like-stuff, right? - but not MixMon) - normal bridged conversations are perfect and do not glitch. It's only when Asterisk is playing back stuff from the filesystem, AND an AGI is launched, does the freeze happen. I believe that (when Asterisk is in this broken state) launching an AGI does something internally to the code that is reading from the filesystem, causing it to freeze for 100msec. Or, at least, a noticable period of time. Now that I have this 'Is the machine broken' code in dialplan, it's very easy to see WHEN it's broken, even if I can't figure out the reason WHY 8-\ My next hypothesis is to kill everything that's connecting to AGI when Asterisk is broken, and see if that fixes it, or at least changes something. By: Joshua C. Colp (jcolp) 2018-07-26 06:47:43.561-0500 ConfBridge isn't doesn't read from the filesystem (except for file playback but that is treated like any other channel in the conference bridge and doesn't block mixing). Normally on the system it will use the timerfd interface of the Linux kernel to provide timing, which uses a file descriptor for its interface. This is polled and a thread whose sole purpose is to mix wakes up at a given interval (20ms) to do the mixing. Even if there's no audio incoming, it still produces a silent frame. The audio is then mixed from the sources and queued to each channel for writing out, after being transcoded to the appropriate format. If ConfBridge didn't send a frame for 100 milliseconds then either every channel was blocked for that period of time (in which case you would see a flood of frames as it catches up) or the timerfd file descriptor didn't wake up within 20ms as it was told to and instead woke up 100ms later and then resumed at a 20ms interval, or the transcoding process in the mixing loop took 100ms to execute. File playback uses the same timing mechanism to time out the frames from disk. If your timing is randomly screwing up and not being reliable, then audio will go wonky. By: xrobau (xrobau) 2018-07-26 07:05:32.477-0500 > didn't wake up within 20ms as it was told to and instead woke up 100ms later and then resumed at a 20ms interval, That's what's happening in the screenshot attached. By: Joshua C. Colp (jcolp) 2018-07-26 07:16:54.723-0500 Then I'd check the timing module in use, if it's not timerfd then change to it. If it's timerfd then you'd need to see if there are mechanisms that the kernel provides to check its timing and diagnose problems with that interface. From the Asterisk side we have a very thin interface over it, but rely entirely on it to provide the timing. There's also a "timing test" CLI command that tests the current timing module in use. By: xrobau (xrobau) 2018-07-26 07:20:36.251-0500 > File playback uses the same timing mechanism to time out the frames from disk. If your timing is randomly screwing up and not being reliable, then audio will go wonky. Awesome! So, thanks to your input, it seems like we've narrowed down where the problem is. For some reason, that timerfd isn't being woken up correctly when an AGI is launched. Is there any debugging I can enable to see if we can isolate where or why it's playing up? By: xrobau (xrobau) 2018-07-26 07:24:31.781-0500 While running 'timing test' on a machine that is NOT glitching, but IS being hammered with AGI calls: {code} -- Goto (from-internal-custom,999,2) -- Executing [999@from-internal-custom:2] GotoIf("Local/999@from-internal-custom-00000c9d;2", "0?toomany") in new stack -- Executing [999@from-internal-custom:3] Gosub("Local/999@from-internal-custom-00000c9d;2", "testtrigger") in new stack -- Executing [999@from-internal-custom:7] AGI("Local/999@from-internal-custom-00000c9d;2", "/bin/true") in new stack -- Launched AGI Script /bin/true uc-85436011*CLI> timing test Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1005 milliseconds, and we got 50 timer ticks -- <Local/999@from-internal-custom-00000c9d;2>AGI Script /bin/true completed, returning 0 -- Executing [999@from-internal-custom:8] Return("Local/999@from-internal-custom-00000c9d;2", "") in new stack -- Executing [999@from-internal-custom:4] Set("Local/999@from-internal-custom-00000c9d;2", "COUNT=115") in new stack -- Executing [999@from-internal-custom:5] Goto("Local/999@from-internal-custom-00000c9d;2", "loop") in new stack -- Goto (from-internal-custom,999,2) -- Executing [999@from-internal-custom:2] GotoIf("Local/999@from-internal-custom-00000c9d;2", "0?toomany") in new stack -- Executing [999@from-internal-custom:3] Gosub("Local/999@from-internal-custom-00000c9d;2", "testtrigger") in new stack {code} Without the AGI hammer, it's 50/1000 exactly. When the machine starts glitching again, I will repeat the test, which I assume may help slightly 8) By: Joshua C. Colp (jcolp) 2018-07-26 07:25:02.221-0500 timerfd is an interface provided by the kernel, we use a thin module[1] to interface with it but the rest is in that land. We don't have any debugging to enable, and I don't know the kernel side of things. It's very much "give me a timer, wake up every 20ms, I acknowledge, rinse and repeat". This also assumes you're using timerfd which I don't know, you could be using dahdi for some reason in which case it's dahdi land. [1] https://github.com/asterisk/asterisk/blob/master/res/res_timing_timerfd.c By: Joshua C. Colp (jcolp) 2018-07-26 07:25:56.797-0500 So timerfd, for whatever reason, took 5ms longer. Why that is - no idea! By: Joshua C. Colp (jcolp) 2018-07-26 07:36:15.080-0500 Back in your court since it so far doesn't seem to be in Asterisk. By: xrobau (xrobau) 2018-07-26 07:36:34.697-0500 Looking at res_timing, this is the only thing that looks like a possible culprit: https://github.com/asterisk/asterisk/blob/master/res/res_timing_timerfd.c#L226 Which is, specifically, 'ao2_lock(timer);' - What if there's some subtle memory issue somewhere, and AGI is locking the wrong thing, and holding that lock up? Anway - there's not much use hypothesizing much more at the moment. It looks like you've pointed the finger at where the issue is, so I at least have a bit of an idea what to think about the next time it happens. I'll update the ticket with what I've found. If you think of anything that can possibly help, please feel free to throw it on the list of things for me to investigate. Things I'm going to do are: * Check the number of open files (ls /proc/$PID/fd - are there an unusually large number of them open, or, are the FD numbers unusually large?) * Run timing test without AGI hammering and with. * Kill anything that's talking to astman (I realise you have said you find it extremely unlikely that it's related, but it's my only straw that links these two machines together at the moment) * Get the output of taskprocessors, iostat and top/htop just to prove that there's nothing system related happening. Anything else you can think of would be great 8) By: xrobau (xrobau) 2018-07-26 07:38:49.484-0500 > Back in your court since it so far doesn't seem to be in Asterisk. If you can give me a rational explanation as to why a simple restart of asterisk fixes it, I'm happy to say 'Yes it is something else', but .... By: Joshua C. Colp (jcolp) 2018-07-26 07:41:41.125-0500 AGI locks very few things using ao2, and only in some specific commands. Timer locks are also unique to every timer, not global. So AGI would have to lock EVERY timer in order to block everything using a timer to cause such a problem. Overwriting that memory would also mean the locks could never recover as they'd be in an undefined state and locks don't take kindly to that, they deadlock. By: Joshua C. Colp (jcolp) 2018-07-26 07:42:50.474-0500 I don't know the timerfd interface internal implementation as I've stated or the interaction it may have with other parts of the system in the kernel and that's not something I'm prepared to dive into. Restarting Asterisk may clear that condition in the kernel resulting in it being fine again for a period of time. If you can find proof based on the information I've provided that it's in Asterisk then we can take a look. By: George Joseph (gjoseph) 2018-07-26 11:09:28.990-0500 I'd take a look at file handles. What does {{ulimit -a}} say for the max allowed? What's {{maxfiles}} set to in asterisk.conf? When the issue happens, how many file handles does the asterisk process have open? {{lsof -p `pidof asterisk` | wc -l}} Of course, closing the asterisk process closes all file handles which may be why that fixes the issue temporarily. If you're running classic AGIs, then asterisk has to spawn a child process to run the AGI in. Can you try AGIs using FastAGI? By: Andrew Nagy (tm1000) 2018-07-26 14:17:33.795-0500 [~gjoseph] So it's a little hard to switch from AGI to FastAGI in freepbx (not impossible), however FastAGI runs in a server environment much like ARI does. So one could say that ARI would be better than FastAGI as well? ARI > FastAGI > AGI By: xrobau (xrobau) 2018-07-26 14:40:55.188-0500 That 48 timer ticks only happened once, and it happened when an AGI was run. It's reliably at 50 when the system is doing anything else APART from AGI() in dialplan. By: Richard Mudgett (rmudgett) 2018-07-26 14:41:05.368-0500 Per the issue guidelines: Please *do not* paste large logs in comments or the issue description. *Attach* the logs as {{.txt}} files to the issue. We've had some people paste megabytes of content in comments that resulted in their issue being inaccessable. By: xrobau (xrobau) 2018-07-26 14:41:44.644-0500 fdlist.txt is a ls of /proc/$PID/fd while asterisk is in this state. By: xrobau (xrobau) 2018-07-26 14:45:11.387-0500 timer_list is the output of /proc/timer_list.txt when the machine is in this state By: Andrew Nagy (tm1000) 2018-07-26 14:45:58.633-0500 As [~rmudgett] requested debug-server.txt uploaded as a file By: George Joseph (gjoseph) 2018-07-26 15:37:37.356-0500 [~tm1000] I was just suggesting that as a test, since you were using /usr/bin/true as the AGI script, if you could do that as a fastagi to another server, you might be able ot tell if it was related to asterisk spawning processes. By: xrobau (xrobau) 2018-07-26 16:34:51.352-0500 After chatting on IRC, another test was proposed in that a seperate Asterisk process is run on the same machine, which runs timing tests at the same time as the live machine. This showed that the timing issue was only in the Asterisk that was suffering from the problem: {code} Active It has been 1000 milliseconds, and we got 50 timer ticks Idle It has been 1000 milliseconds, and we got 50 timer ticks Active It has been 1000 milliseconds, and we got 50 timer ticks Idle It has been 1000 milliseconds, and we got 50 timer ticks Active It has been 1011 milliseconds, and we got 46 timer ticks Idle It has been 1000 milliseconds, and we got 50 timer ticks Active It has been 1000 milliseconds, and we got 49 timer ticks Idle It has been 1000 milliseconds, and we got 50 timer ticks Active It has been 1000 milliseconds, and we got 50 timer ticks Idle It has been 1000 milliseconds, and we got 50 timer ticks {code} You'll see that the 'Active' machine slipped twice. This, actually, confirms what I posted earlier - running a large number of AGI's causes timing to slip: {code} uc-85436011*CLI> timing test Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1005 milliseconds, and we got 50 timer ticks {code} Looking at the code of timing test: https://github.com/asterisk/asterisk/blob/master/main/timing.c#L252 That loop is based on time, so being that it ran *long*, it feels to me that ast_poll is delaying internally for some reason. So, this now appears that this IS something that is better described as "ast_poll can suffer delays when AGI calls are spawned" - and that IS replicable! By: xrobau (xrobau) 2018-07-26 17:57:25.389-0500 I managed to get my test machine to the state where the audio is bad. Attached is 'broken.pcap' of a call that is using the dialplan in the description of the ticket. This is *not* showing a lockup of 100msec, so it looks like that was a red herring, too, and that was just a coincidence. By: xrobau (xrobau) 2018-07-26 18:04:42.707-0500 As per George Joseph's suggestion, I pinned asterisk to CPU0, and the AGI() audio glitch is still present. Also, this is NOT showing slippage on timing test. The following was run with the AGI hammer active, and the MoH audio awful, and no slippage was seen {code} [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'timerfd' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx ~]# {code} So this is now back at NOT being timerfd related now? I'm going to see what I did to cause this, and work on duplicating this repeatedly. By: Joshua C. Colp (jcolp) 2018-07-26 18:07:40.764-0500 You haven't defined what bad means and what is actually executing, since that dialplan calls outside as well. Is it the beep that is "bad"? By: Joshua C. Colp (jcolp) 2018-07-26 18:09:25.580-0500 Some kind of additional logging is probably needed to show the actual time spent doing things. Forking the AGI process, polling, that kind of thing. By: xrobau (xrobau) 2018-07-26 20:32:27.357-0500 I could hear it quite easily on the pcap, but here's a video if that makes it more obvious https://www.youtube.com/watch?v=XSpUYZWaYMs This is what we know so far (or what I think I know) 1. Something causes Asterisk to get into this confused state. I can't isolate EXACTLY what it is, but I can, with some fiddling, get my test machine into that state. 2. When it's confused, running the AGI() command in Dialplan causes everything that is reading from a file (and ConfBridge) to briefly pause sending RTP traffic. 3. When it's confused, launching an AGI command takes significantly longer. I assume this is related, and it's the actual launching-of-the-AGI that is what's blocking everything. 4. There appears to be no way to un-confuse Asterisk, apart from restarting it. 5. Normal bridged RTP is not affected. That works fine, and no delay is apparent. By: xrobau (xrobau) 2018-07-26 23:10:53.803-0500 I may have found another common factor. When things go bad, I find this in the logs: {code} var/log/asterisk/full-[2018-07-26 12:43:39] WARNING[10389] taskprocessor.c: The 'app_voicemail' task processor queue reached 500 scheduled tasks again. /var/log/asterisk/full-[2018-07-26 12:43:39] ERROR[23418] astobj2.c: Excessive refcount 100000 reached on ao2 object 0x28946d0 /var/log/asterisk/full:[2018-07-26 12:43:39] ERROR[23418] astobj2.c: FRACK!, Failed assertion Excessive refcount 100000 reached on ao2 object 0x28946d0 (0) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: Got 29 backtrace records /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #0: [0x5fc445] asterisk __ast_assert_failed() (0x5fc3c1+84) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #1: [0x45e00f] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #2: [0x45e368] asterisk __ao2_ref() (0x45e33a+2E) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #3: [0x5ceb86] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #4: [0x5ced09] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #5: [0x5c635c] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #6: [0x5c704b] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #7: [0x5c7333] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #8: [0x5c73a2] asterisk stasis_publish() (0x5c737a+28) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #9: [0x5c7e26] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #10: [0x5c6607] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #11: [0x5c669a] asterisk stasis_subscribe_pool() (0x5c6667+33) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #12: [0x7fd077c67f19] res_pjsip_mwi.so <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #13: [0x7fd077c69476] res_pjsip_mwi.so <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #14: [0x45f120] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #15: [0x45f43d] asterisk __ao2_callback() (0x45f3e1+5C) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #16: [0x7fd077c69cf8] res_pjsip_mwi.so <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #17: [0x7fd077c69d52] res_pjsip_mwi.so <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #18: [0x536694] asterisk ast_module_reload() (0x53632c+368) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #19: [0x4cfbc1] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #20: [0x4d7cbd] asterisk ast_cli_command_full() (0x4d7a4c+271) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #21: [0x4d7e00] asterisk ast_cli_command_multiple_full() (0x4d7d64+9C) /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #22: [0x454b71] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] VERBOSE[23418] logger.c: #23: [0x5f93f8] asterisk <unknown>() /var/log/asterisk/full-[2018-07-26 12:43:39] ERROR[23418] astobj2.c: Excessive refcount 100000 reached on ao2 object 0x28946d0 /var/log/asterisk/full:[2018-07-26 12:43:39] ERROR[23418] astobj2.c: FRACK!, Failed assertion Excessive refcount 100000 reached on ao2 object 0x28946d0 (0) ... (another identical stack trace) ... {code} That was on the client's machine, which is just in normal production, without any load tests being run on it. When I'm running the load test locally to try to give you a decent replication, I do - eventually - get FRACK errors about too many refcounts on ao2 objects which almost ALWAYS signify that the machine is now broken. The FRACK error I can reliably reproduce requires CEL to be enabled, and the test trigger to be similar to this: {code} same => n,Dial(SIP/8675309@127.0.0.1:5160,1,g) {code} To reproduce this yourself, you just need to deploy a standard FreePBX 14 machine, enable anonymous inbound SIP and then run the loop in the original description with that as the trigger. Wait for it to FRACK a few times, and then replace it with AGI(/bin/true) and you will see the problem. If it will be more convenient for you, I can provide you access to the actual hardware that can reliably reproduce this, which is already configured and ready to go. By: Joshua C. Colp (jcolp) 2018-07-27 06:15:58.935-0500 This is a patch which outputs how long it takes the AGI to fork. From my quick Googling it may be that the more memory usage there is (and based on your logs there are lots of queued things and such) the longer it takes to fork. During the forking process it may be blocking things such to cause audio problems (this is a theory - this is down below us again and I don't know the ramifications on the entire process of this). By: Joshua C. Colp (jcolp) 2018-07-27 06:29:38.579-0500 Heck, you could also switch to using the dahdi timing module instead of timerfd and see what impact that has. It operates differently, so if it's fine in the scenario then it's been narrowed down further. Not loading any timing module may even work - I think the core still allows that for playback and music on hold. By: Joshua C. Colp (jcolp) 2018-07-27 08:03:23.241-0500 I'll also add that FastAGI is made to be, well, fast and not suffer from the slowdown or problems that forking a process each time incurs. It's superior to normal AGI and performs better in high load and high usage scenarios. By: xrobau (xrobau) 2018-07-27 16:37:54.950-0500 Thanks Josh! Your suggestion to use Dahdi timing has proved, beyond a shadow of a doubt, that timerfd is the problem. When I added the following lines to modules.conf, even though the AGI execution rate slowed down, there were no audio glitches present: {code} noload = res_timing_timerfd.so noload = res_timing_kqueue.so {code} {code} [root@freepbx asterisk]# asterisk -rx 'timing test' Attempting to test a timer with 50 ticks per second. Using the 'DAHDI' timing module for this test. It has been 1000 milliseconds, and we got 50 timer ticks [root@freepbx asterisk]# {code} The timing is no longer as accurate (as soon as there is any load on the machine, the time varies by up to +50msec), but the audio is still perfect. As per our discussions on IRC, I believe we're both in agreement that the actual fork() system call is blocking the poll() on timerfd from returning. This causes the audio glitch because all of the tasks mentioned in this ticket are reliant on timerfd returning accurately. As I can reasonably reliably replicate this, I'm going to switch back to running this on a VM, so it is easier and faster to manage. Assuming I can still replicate this in a VM, my next test is to replicate this on a newer OS (Ubuntu 18) and see if this is something that is already fixed. Edit: Additional debugging has confirmed that fork() itself is taking a long time, and matches up with the audio glitches. By: xrobau (xrobau) 2018-07-27 17:06:57.796-0500 I realised it would just be simpler to use a newer kernel on my existing machine. The latest mainstream kernel still has the same issue. {code} [root@freepbx ~]# uname -a Linux freepbx.sangoma.local 4.17.10-1.el7.elrepo.x86_64 #1 SMP Wed Jul 25 15:25:01 EDT 2018 x86_64 x86_64 x86_64 GNU/Linux [root@freepbx ~]# {code} By: xrobau (xrobau) 2018-07-27 21:23:17.966-0500 Now that you guys managed to help me nail it down to being inside fork(), that let me write some test code to validate the problem, which is attached as forktest.c (MIT Licence). This let me confirm that it only happens on RHEL7 machines: {code} [root@freepbx g]# gcc -v Using built-in specs. COLLECT_GCC=/usr/bin/gcc COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper Target: x86_64-redhat-linux Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux Thread model: posix gcc version 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC) [root@freepbx g]# gcc -O2 -o f forktest.c [root@freepbx g]# time ./f Time taken per fork: 0.000257 Time taken with 500MB: 0.001201 Time taken with 1GB: 0.002084 Time taken with 2GB: 0.003870 Time taken with 4GB: 0.007358 real 0m3.324s user 0m0.362s sys 0m2.957s [root@freepbx g]# {code} This does NOT happen on newer machines. This left (what I thought) was two variables, the kernel - which I had already crossed off - and glibc. I tried installing a secondary glibc, and that did NOT speed up the fork()'s. However, as part of building a new glibc, I needed to install a new gcc as well. {code} [root@freepbx g]# gcc -v Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/opt/rh/devtoolset-7/root/usr/libexec/gcc/x86_64-redhat-linux/7/lto-wrapper Target: x86_64-redhat-linux Configured with: ../configure --enable-bootstrap --enable-languages=c,c++,fortran,lto --prefix=/opt/rh/devtoolset-7/root/usr --mandir=/opt/rh/devtoolset-7/root/usr/share/man --infodir=/opt/rh/devtoolset-7/root/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-shared --enable-threads=posix --enable-checking=release --enable-multilib --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-gcc-major-version-only --enable-plugin --with-linker-hash-style=gnu --enable-initfini-array --with-default-libstdcxx-abi=gcc4-compatible --with-isl=/builddir/build/BUILD/gcc-7.3.1-20180303/obj-x86_64-redhat-linux/isl-install --enable-libmpx --enable-gnu-indirect-function --with-tune=generic --with-arch_32=i686 --build=x86_64-redhat-linux Thread model: posix gcc version 7.3.1 20180303 (Red Hat 7.3.1-5) (GCC) [root@freepbx g]# gcc -O2 -o f forktest.c [root@freepbx g]# time ./f Time taken per fork: 0.000250 Time taken with 500MB: 0.000248 Time taken with 1GB: 0.000248 Time taken with 2GB: 0.000247 Time taken with 4GB: 0.000245 real 0m0.125s user 0m0.074s sys 0m0.063s [root@freepbx g]# {code} This is still using the older glibc, which confirms it is a compiler issue, not a glibc issue: {code} [root@freepbx g]# ldd -v ./f linux-vdso.so.1 => (0x00007ffc4f32a000) libc.so.6 => /lib64/libc.so.6 (0x00007fcc1f5a8000) /lib64/ld-linux-x86-64.so.2 (0x00007fcc1f975000) Version information: ./f: libc.so.6 (GLIBC_2.2.5) => /lib64/libc.so.6 /lib64/libc.so.6: ld-linux-x86-64.so.2 (GLIBC_2.3) => /lib64/ld-linux-x86-64.so.2 ld-linux-x86-64.so.2 (GLIBC_PRIVATE) => /lib64/ld-linux-x86-64.so.2 [root@freepbx g]# {code} By: xrobau (xrobau) 2018-07-27 22:29:47.154-0500 Sigh. Unfortunately, this is just newer versions of GCC being smarter about what to optimize out, and it is actually optimizing out the malloc()s. SO that is not a solution. The best answer we have, at the moment, is not to use timerfd on heavily loaded systems. By: Joshua C. Colp (jcolp) 2018-08-02 18:04:55.149-0500 I've assigned this back to you since stuff has been isolated and there's nothing on our side to do. If there's anything else, just comment and it'll transition back. By: xrobau (xrobau) 2018-08-05 13:31:32.150-0500 Currently, we've had significant success with switching people to DAHDI timing who are running AGIs on loaded systems. This should probably be on the Wiki somewhere, as this is now a known issue with pretty bad effects 8-\ In the interim, we're looking at how much of an effort it's going to be to rewrite everything using fastagi (a lot), and when we can do it (not soon). As I've been unable to duplicate this in some simple code, I've been wondering if the poll() call is being picked up in the child process, leaving the parent process blocked. That would explain why it's not complaining about multiple timerfd events being received. Does that sound plausible to you? I can't think of how to FIX it though. By: Joshua C. Colp (jcolp) 2018-08-05 14:58:57.591-0500 I don't know the possible interaction there, so no idea. That being said - poll() is used for everything including RTP, so if it were some kind of widespread problem other things should be impacted as well. If there's a wiki page that would make sense to put it on or a documentation location then we can certainly see about updating it, but you'd need to state where you would have expected it to be. By: xrobau (xrobau) 2018-08-06 14:56:53.187-0500 >That being said - poll() is used for everything including RTP, OK, makes sense - so it's something at a deep kernel level impacting ONLY timerfd when fork() is called. > If there's a wiki page that would make sense to put it on or a documentation location then we can certainly see about updating it, but you'd need to state where you would have expected it to be. I don't know. I think a pretty big notice on the AGI wiki page, as well as in the release notes or something? It's a non-fixable issue that causes awful audio problems, with a reasonably simple workaround. I don't have permissions to edit the wiki page(s?) so if you could grant me edit perms, I could go in there and add some notes and a warning. Also, and it makes me feel dirty even saying this, I will probably go and make some notes on voip-info, too. Re FreePBX, in our Triage meeting today we discussed the possibility of moving everything to FastAGI for FreePBX 15, and it may be possible to squeeze that in. Otherwise it'll be done for 16. By: Malcolm Davenport (mdavenport) 2018-08-06 15:19:52.606-0500 Try editing wiki pages now. You'll need to log in separately. By: Joshua C. Colp (jcolp) 2018-08-14 10:07:45.579-0500 As there's nothing else to do here I'm closing this out. If you have trouble accessing the wiki just comment and this will reopen. | ||
{kind=link}
{kind=link}